
Il file Robots.txt è un semplice file di testo che è possibile piazzare nella root del sito per istruire i motori di ricerca su quali cartelle del sito deve indicizzare regolarmente e quali non deve indicizzare affatto. Questo file è letto dalla maggior parte dei motori di ricerca ed è di estrema utilità per una buona ottimizzazione per i motori di ricerca.
Il file Robot.txt
Nello scorso articolo abbiamo visto come risulti cruciale identificare quale contenuto debba essere reso invisibile ai motori di ricerca; in nostro aiuto ci viene il Robots Exclusion Protocol (REP), un protocollo che vieta l’accesso da direttori specificati all’intero sito. Il protocollo REP effettua controlli che possono essere applicati sia a livello globale attraverso il file robots.txt, sia a livello di pagina (come abbiamo visto precedentemente nello scorso articolo).
Il file Robots. txt è un semplice file di testo codificato in formato UTF-8, che contiene comandi consistenti e una o più direttive che specificano quali contenuti il motore dovrà analizzare per indicizzarli regolarmente. Il file Robots.txt dovrà sempre trovarsi nella directory principale del proprio dominio. Per esempio, www.ingegneridelweb.com/Robots.txt è la posizione corretta per il file Robots.txt all’interno del dominioingegneridelweb.com.
Nota
Dobbiamo sottolineare come per ogni sottodominio sarebbe opportuno applicare un opportuno file robots.txt. Allo stesso tempo, però, tale file si applica a tutte le directory e sotto directory presenti nello stesso dominio o sottodominio.
Vediamo ora come utilizzare correttamente questo file per istruire gli spider dei motori di ricerca:
# Blocca l'accesso a tutti gli spider alla cartella admin e al suo contenuto User-agent: * Disallow: /admin
- User Agent indica a quale robot il comando si applica; è possibile definire il valore * (asterisco) per specificare che tale comando viene applicato a tutti i robot. Se vogliamo invece che l’azione sia specifica per un determinato crawler di un motore di ricerca, possiamo specificare il valore;
- Disallow serve a indicare qual è il contenuto da bloccare. Deve iniziare con / e può essere usato con alcune combinazioni di caratteri speciali.
| Nome Robot/strong> | Funzione |
| Googlebot | Analizza le pagine web |
| Googlebot-Mobile | Analizza le pagine web per mobile |
| Googlebot-Image | Analizza le immagini |
| Mediapartners-Google | Analizza i contenuti AdSense |
| AdsBot-Google | Analizza i contenuti AdWords |
| Yahoo! | |
| Slurp | Analizza le pagine web |
| Yahoo-MMCrawler | Analizza le immagini |
| Yahoo-MMAudVid | Analizza i contenuti video |
| Bing | |
| MSNBot | Analizza le pagine web |
| MSNBot-Media | Analizza i contenuti multimediali |
| MSNBot-News | Analizza i feed delle news |
Tabella 1: I crawler dei maggiori motori di ricerca
Nota
Nel seguente articolo potete prendere visione dei nomi dei principali crawler utilizzati dai motori di ricerca: ABCdatos BotLink
Vediamo alcuni esempi
Blocca l’accesso al documetno mo.html, da parte di tutti gli spider
# Blocca l'accesso a tutti gli spider al file mio.html User-agent: * Disallow: /mio.html
Blocco l’accesso al solo spider di Google a tutti i file che hanno estensione pdf:
# Blocca l'accesso a Google a tutti i file con estensione pdf User-agent: googlebot Disallow: /*.pdf$
Questo esempio è più curioso nella prima riga del Disallow blocco l’accesso a Google alla directory tmp, mentre nella riga sottostante viene bloccato l’accesso sia ai file, sia alle directory pippo.
# Blocca l'accesso a Google alla directory tmp e alla directory e i file pippo User-agent: googlebot Disallow: /tmp/ Disallow: /pippo #blocca le directory e i file "pippo" per esempio pippo.html
Blocca tutti i robot; è da utilizzarsi quando il proprio sito è in fase di testing e non ancora pronto per essere indicizzato o per i sottodomini riservati.
# Blocca l'indicizzazione dell'intero sito web User-agent: * Disallow: /
Per consentire l’accesso a tutti gli spider del sito dobbiamo lasciare uno spazio vuoto dopo i due punti che seguono la dicitura Disallow.
#Il sito è completamente accessibile a tutti gli spider User-agent: * Disallow:
Nell’esempio sotto riportato inibisco l’accesso a tutte le cartelle tranne alla cartella public.
# Abilito soltanto una cartella all'accesso dello spider User-agent: * Disallow: / Allow: /public/
Impedisce la scansione di URL che includono il punto interrogativo
# Block access to URLs that contain ? User-agent: * Disallow: /*?
Prima di scansionare una pagina Bing deve aspettare 2 secondi
# Lo spieder di Bing deve aspettare 2 secondi prima di scansionare un'altra pagina User-agent: msnbot Crawl-delay: 2
Il ritardo è supportato da Yahoo!, Bing e Ask. Incarica un crawler di aspettare il numero specificato di secondi tra una scansione e l’altra. L’obiettivo della direttiva è quello di ridurre il carico sul server.
User-agent: * Disallow: /include/ Request-rate: 1/5 Visit-time: 0910-1235
L’esempio mostra due nuovi parametri:
- REQUEST-RATE: utilizzato per istruire lo spider a visitare al massimo n pagine ogni tot secondi (nel nostro caso 1 pagina ogni 5 secondi);
- VISIT-TIME: per indicare il lasso di tempo in cui lo spider può accedere, nel nostro caso può accedere dalle 9:10 fino alle 12:35.
Nota
Nel seguente articolo potete trovare ulteriori spiegazioni sull’utilizzo avanzato dei comandi per il file robots.txt: An Extended Standard for Robot Exclusion
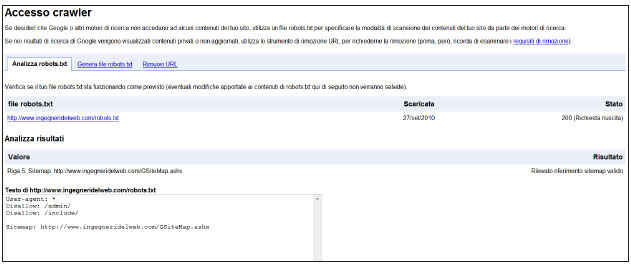
Infine, l’ultimo esempio proposto serve a dare un aiuto agli spider a individuare la sitemap del nostro sito web . Ricordiamo, inoltre, che attraverso lo strumento Google Webmaster Tools (GWT), è possibile monitorare la corretta installazione del file Robots.txt.
User-agent: * Sitemap: http://www.sito.com/GSiteMap.ashx
Nota
È importante sottolineare il fatto che mettere il tag “Disallow” a una determinata directory non implica che essa non possa essere disponibile via web e quindi protetta da eventuali attacchi di malintenzionati. Utenti curiosi potrebbero analizzare il vostro file robots.txt per vedere le cartelle “protetprotettete” e cercare di accedervi. Per questo motivo è fondamentale proteggere con password o con sistemi di cifratura lato server le directory o i file riservati.
Autore: Marco Maltraversi – Consulente SEO – Tratto da: SEO e SEM – Edizioni FAG